
基于FastText的文本分类
数据集说明
数据大小
• 训练集:20万条样本,文件大小约839M
• 测试集:5万条样本,文件大小约210M
分类类别:14类
• {科技: 0, 股票: 1, 体育: 2, 娱乐: 3, 时政: 4, 社会: 5, 教育: 6, 财经: 7, 家居: 8, 游戏: 9, 房产: 10, 时尚: 11, 彩票: 12, 星座: 13}
匿名处理 • 将文本转换为与之对应的数字
FastText的使用
根据FastText要求准备训练集、验证集
• 一行一条样本 • 一行样本包含文本与标签
• 文本与标签使用制表符隔开
• 给标签加上"label"前缀
导入包、训练模型 • import fasttext • model = fasttext.train_supervised(input=“train.txt”)
保存模型、加载模型 • model.save_model(“model.bin”) • model.load_model(“model.bin”)
模型评估、测试推理 • model.test(input=“val.txt”) • model.predict(test_data)
数据处理
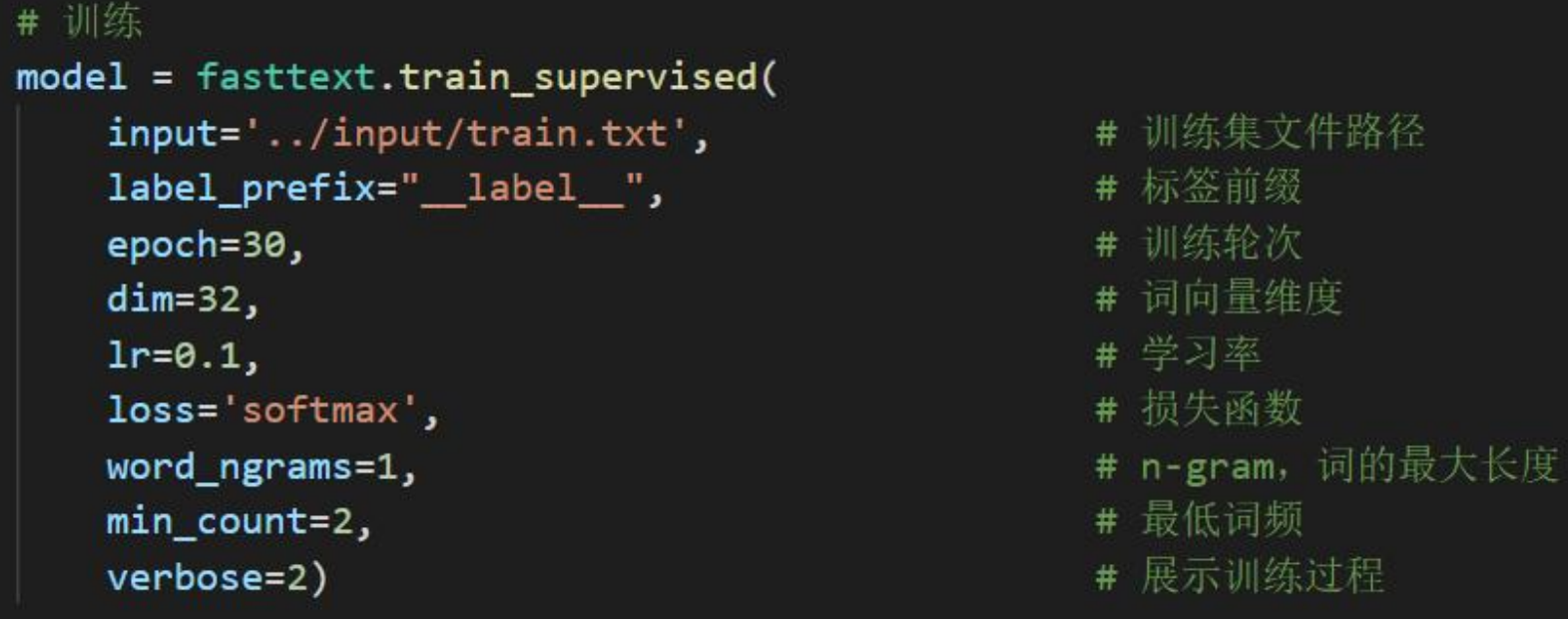
执行data_process.py文件,具体步骤如下:
-
使用Pandas读取train.csv文件
-
对数据进行随机打散
-
给标签列“label”加上“label”前缀
-
抽取倒数500行作为验证集
-
使用Pandas将处理好的训练集与验证集保存为txt格式
模型训练
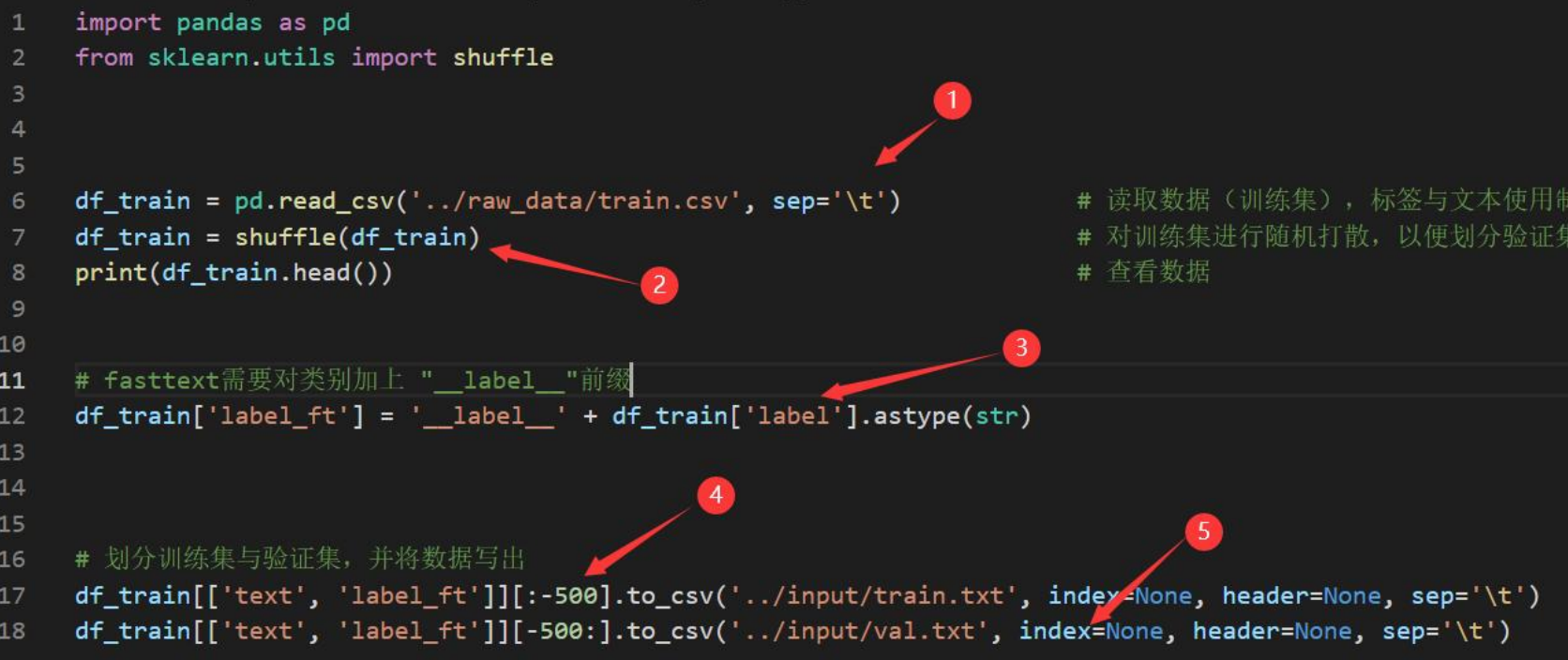
执行train.py文件,具体步骤如下:
-
导入fasttext库
-
使用fasttext.train_supervised()训练模型,并设置相应的参数
-
使用model.save_model()将训练好的模型保存起来
-
使用model.test()训练好的模型对验证集进行评估
-
计算F1值,并将所有的评估指标打印出来
预测推理
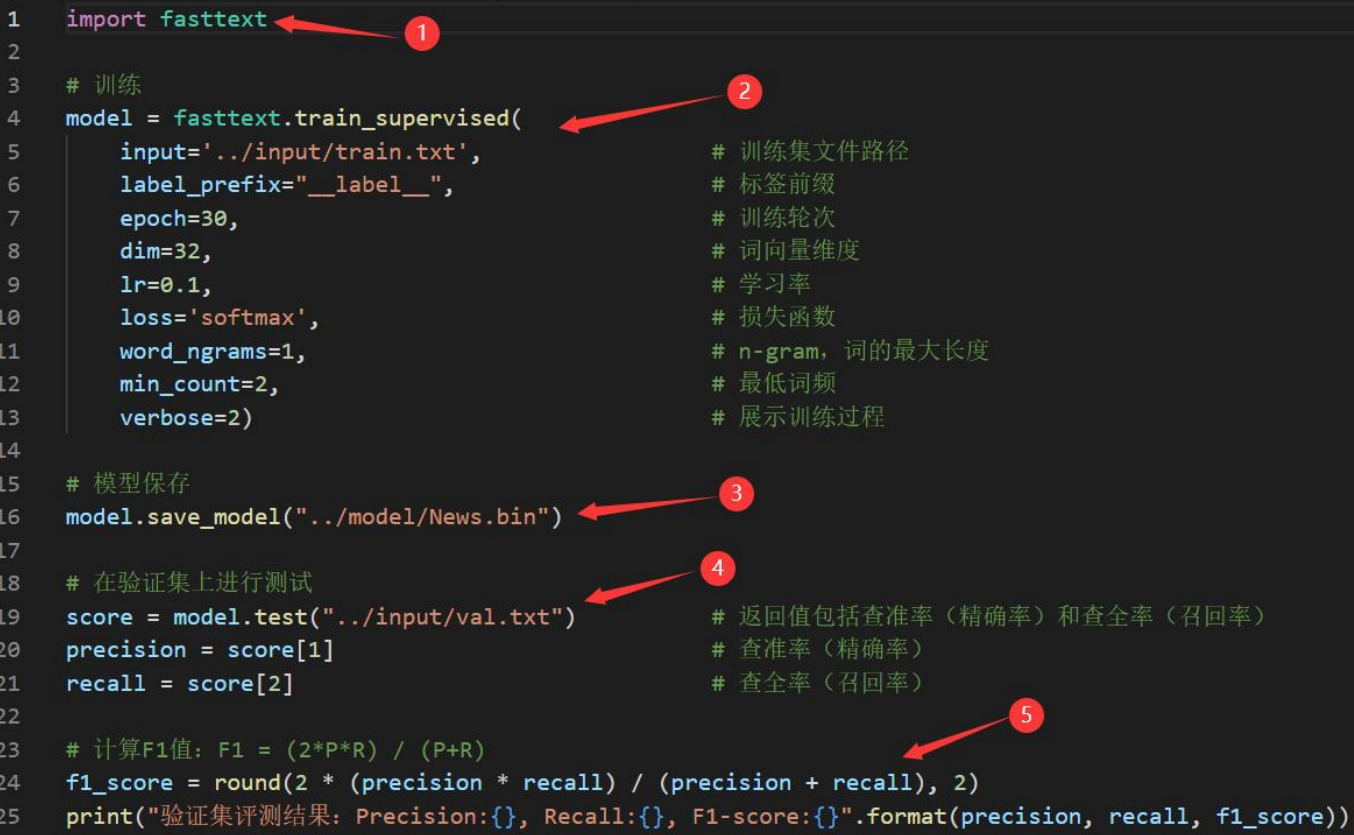
执行predict.py文件,具体步骤如下:
-
导入fasttext、Pandas库,使用fasttext加载训练好的模型,使用Pandas读取测试集
-
将预测集中文本列取出,并将数据格式转换为列表,然后调用model.predict()进行 预测
-
对预测结果进行处理,并将处理后的预测结果作为新的列添加至预测集中,列名 为“label_pre”
-
将预测结果写出到output路径中,文件名为“ predict.csv”
-